여기서 스택(stack)이라고 하는 것은 계층별로 다른 기술들이 중첩된(쌓여있는) 모양을 이야기 하는데, 예를 들어 프로토콜 스택이라고 하면 OSI 7레이어처럼 각 계층마다 다른 기술들이 독립적으로 쓰일 수 있는 모양을 의미한다. 빅데이터에서도 계층별로 다양한 기술들이 쏟아져 나오고 있기 때문에 스택으로 생각하면 편하다.
빅데이터 스택
스택을 얘기하기 전에 빅데이터의 기능 요구사항(functional requirement)을 먼저 생각해 보자. 빅데이터를 얘기할 때는 데이터를 어떻게 수집(capture)하고, 구성(organize)하고, 통합(integrate)하고, 분석(analyze)하고, 행동(act)할 것인지를 생각해야 한다. 여기서 구성하고 통합한다는 것은 여러개의 파편화된 데이터이지만 하나의 개체에 대한 것이라면 엮어서 합치는 것을 의미한다. 이렇게 해야 의미있는 분석이 이루어진다.
 |
| By Natasha Balac |
빅데이터 기술들은 데이터 레이어, 분석 레이어, 서비스 레이어로 나누어 스택처럼 생각할 수 있다. 데이터 레이어와 분석 레이어에서는 취급할 수 있는 크기(scale)와 처리 속도를 기준으로 기술의 성능을 구분할 수 있다.
예를 들어 데이터 레이어에 해당하는 Hadoop은 큰 크기를 다룰 수 있지만 실시간성이 떨어지고, Esper는 반대로 빠른 이벤트 처리가 가능하다. (빠른 데이터 처리에 촛점을 맞추어 High Velocity Data라는 용어도 사용한다)
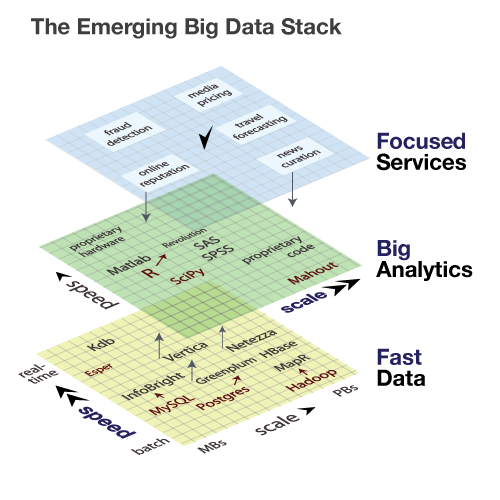 |
| By Michael Driscoll, O'Reilly Radar |
빅데이터 분야는 발전이 빠른 분야기 때문에 새로운 제품과 용어가 계속 등장하고 있다. 아래 그림과 같이 빅데이터 스택을 더 세분화하여 각 기술과 제품들을 정리하면 헷갈리지 않고 이해가 쉽다. (그런데 빅데이터 스택은 프로토콜 스택과는 달리 계층간의 독립성이 보장되지 않는 경우가 많은 것 같다. 예를 들어 Mongodb나 MySQL이 하위에 Hadoop을 둘 수 없다.)
 |
| By Ravi Padaki, Data Kulfi |
빅데이터 기술 지도
많은 빅데이터 기술과 제품을 잘 분류하는 것도 일인데, 이렇게 해 놓은 것을 빅데이터 지도(landscape)라고 한다. (어떻게 보면 빅데이터 제품의 갯수 자체도 빅데이터인 듯) 각자의 상황에 맞는 다양한 솔루션들이 시장에 나와 있는데, 한마디로 "바글바글한 다양성의 공간(crowded diverse space)"이라고 말할 수 있다. 이 기술들을 분야별로 나누어 보면 아래 그림과 같다.
 |
| By Matt Turck |
더 골치아픈 것은 지난 1년 동안 빅데이터 관련 회사가 거의 두배로 늘었다는 것이다. 빅데이터 기술의 전화번호부라고 할 수 있는 랜드스케이프가 더욱 복잡해졌다. 빅데이터의 여러 분야 중에서도 마케팅 관련 회사가 급증했다는 특징이 있다.
 |
| By chiefmartec.com |
(너무 빽빽해서 그림을 알아볼 수가 없는데, 확대 가능한 원본은 이 링크에 있음. 혹은 랜드스케이프를 온라인에서 관리하는 http://www.bigdatalandscape.com를 참고할 것.)
빅데이터에 필요한게 뭐냐?
빅데이터 기술의 인프라에 요구되는 것은 실시간성(real-time), 확장성(scalable), 고성능(high performance)이다. 지난 몇년 동안 빅데이터가 주목을 받았지만, 많은 데이터를 처리할 수 있는 컴퓨팅 인프라가 결핍되어 있었다. 그동안 컴퓨터 하드웨어는 해마다 그 성능을 높여왔지만, 빅데이터는 몇대의 서버 만으로 처리할 수 있는 양이 아니다.
예전에는 두 세트의 데이터베이스 서버가 서비스의 모든 데이터를 중앙집중 보관하였고, 웹서버/미들웨어 서버는 오로지 계산만 수행하였다. 이런식의 전통적인 구성은 처리할 수 있는 데이터의 양이 어떤 한계를 넘어서기 어려웠다.
그래서 생각해낸 것이 고만고만한 컴퓨터들을 많이 엮어놓고, 그 컴퓨터가 저장과 계산(compute + storage)을 모두 하게 하자는 것이다. 바로 이것이 Hadoop이 하고자 하는 것이다. Apache재단의 Hadoop 프로젝트는 안정적이고 확장성을 제공하는 분산 컴퓨팅을 위한 오픈소스 인프라이다.

Hadoop의 사명(mission statement)은 "커다란 데이터들을 평범한 서버(commodity)로 구성된 클러스터들에 분산 배치하고 처리"하는 것이다. 더불어 Hadoop은 단순한 프로그래밍 모델을 사용하며, 저렴한 서버들을 간편하게 늘려 용량과 성능을 확장할 수 있게 한다.
Hadoop은 일반적인 시스템이 다루기에 너무 큰 데이터들을 다루기 위해 만들어 졌다. Hadoop은 한대로 구성될 수도 있고, 수천대의 컴퓨터로 구성될 수도 있다. 확장성은 기본이고, 중간에 서버 중 일부가 파손되더라도 데이터를 잃지 않고 서비스를 지속할 수 있는(fault tolerant) 안정성도 제공한다.
Hadoop이 인기있는 이유는...
- 적은 비용으로 구축할 수 있다 : 저렴한 서버들을 늘리기만 하면 되므로
- 확장성 : 새로운 서비스를 구축하고 증설하는것이 매우 쉬움
- 안정성 : fault-tolerant, 서버 한대가 다운되더라도 자동으로 재배치를 해 서비스가 중지되지 않음
- 유연한 환경 : 스키마-프리(schema-free) 지원, 정형/비정형 데이터 모두 처리 가능
Hadoop은 여러가지 배포판(distributions)이 존재한다. 오리지널은 Apache재단이지만, Cloudera, Hortonworks, MAPR, Amazon, Intel, Pivotal 등에서 커스터마이즈된 배포판을 내놓고 있다.
 |
| By Xomnia |



댓글 없음:
댓글 쓰기